6. Stream API¶
In the previous chapter you saw how streams are related to collections, various stream sources and kind of stream operations. In this chapter we will have an extensive look at various operations supported by stream API. java.util.stream.Stream contains numerous methods that let you deal with complex data processing queries such as filtering, slicing, mapping, finding, matching and reducing both in sequential and parallel manner. There are also primitive specialization of streams used for primitive elements and contains additional operations min, max, sum etc.
6.1. Filtering¶
Stream interface provides a method filter which accepts a Predicate as argument and return a stream that matches the given predicate. The predicate will be applied to each element to determine if it should be included to new stream.
| Signature: | Stream<T> filter(Predicate<? super T> p) |
|---|
// Finding words starts with vowel
List<String> words = Stream.of("apple", "mango", "orange")
.filter(s -> s.matches("^[aeiou].*"))
.collect(toList());
:Output: [apple, orange]
6.2. Truncating Stream¶
Stream supports the limit(n) method accepts a numeric value and returns a new stream consisting of the elements of this stream, truncated to be no longer than maxSize in length. If the stream length is less than the given size then complete stream will be returned.
limit will truncate the stream from end where as there is another method called skip(n) will discard elements from begining.
| Signature: | Stream<T> limit(long maxSize) Stream<T> skip(long n) |
|---|
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
stream.filter(i -> i%2 == 0).limit(2).collect(toList());
stream.filter(i -> i%2 == 0).skip(1).collect(toList());
6.3. Consuming Stream¶
Stream provides two methods peek and forEach which accepts a Consumer as argument and performs the action on each element.
| Signature: | Stream<T> peek(Consumer<? super T> action) void forEach(Consumer<? super T> action) |
|---|
The peek is an intermediate operation which returns the new stream where as forEach is the terminal operation returns void.
Stream<Integer> stream = Stream.of(1, 2, -3, 4, 5);
stream.filter(i -> i%2 == 0).peek(System.out::println).toArray();
stream.filter(i -> i%2 == 0).forEach(System.out::println);
See also
forEachOrdered, performs action on encontered order.
6.4. Mapping¶
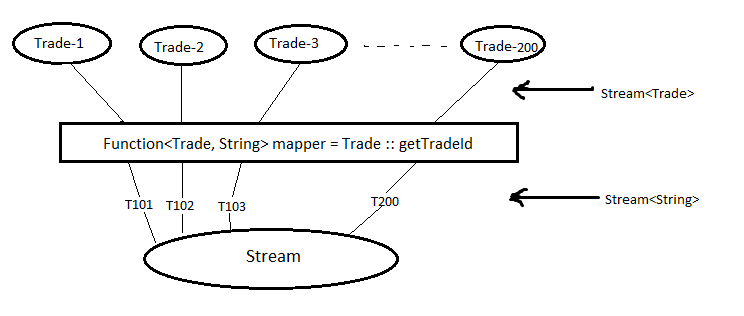
A very common data processing idiom is to select information from a certain object. For example selecting trade id from an Trade object. Stream supports map method which accepts a Function as argument and returns a new stream consisting of the results of applying the given function to the elements of this stream.
| Signature: | <R> Stream<R> map(Function<? super T, ? extends R> mapper) |
|---|
List<Trade> trades = new ArrayList<>();
trades.add(new Trade("T101", "Paul", 5000, "USD", APAC));
trades.add(new Trade("T102", "Mr Bean", 3580, "SGD", NA));
trades.add(new Trade("T103", "Simond", 2300, "CAD", EMEA))
trades.stream().map(Trade::getTradeId).collect(Collectors.toList());
Output: [T101, T102, T103]
There are primitive variants of map methods mapToInt, mapToDouble and mapToLong that we will see later. Stream interface has method flatMap which returns a stream consisting of the results of replacing each element of this stream with the contents of a mapped stream produced by applying the provided mapping function to each element. Sometime each element of a stream will produce individual streams that will be amalgamated into single stream and flatMap will be used there. It might be confusing you now so let see an example where you need to find distinct words contained in a file. Here we will use File.lines() which will return Stream<String> where each element will represent to a single line of the file.
List<String> words =
Files.lines(Paths.get("flatmap.txt")) // Stream<String>
.map(line -> line.split(" ")) // Stream<String[]>
.map(Arrays::stream) // Stream<Stream<String>>
.distinct()
.collect(Collectors.toList());
System.out.println(words);
In the above code snippet each line will be splitted to array of words. Each array of words then passed to Arrays.stream() which will return Stream<String> for every line. map(Arrays::stream) will return Stream<Stream<String>> so our final output will be List<Stream<String>> where as our requirement is List<String>.
Now if you replace map(Arrays::stream) with flatMap(Arrays::stream) then all the elements from the each inner stream will be merged to a single outer stream.
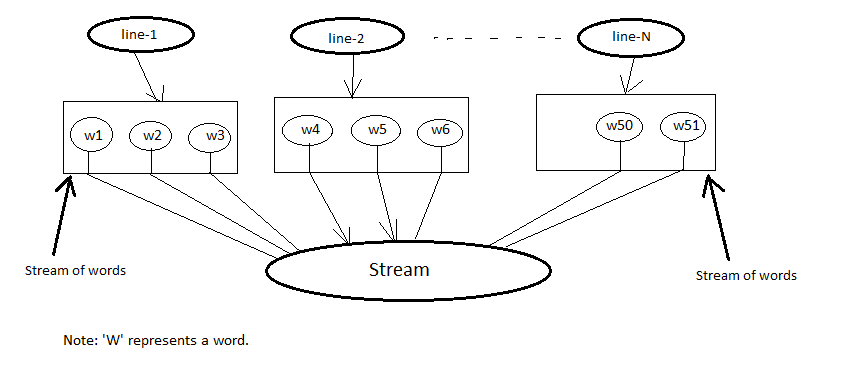
List<String> words =
Files.lines(Paths.get("flatmap.txt")) // Stream<String>
.map(line -> line.split(" ")) // Stream<String[]>
.flatMap(Arrays::stream) // Stream<String>
.distinct()
.collect(Collectors.toList());
System.out.println(words);
6.5. Matching¶
Stream API provides anyMatch, allMatch and noneMatch short-circuiting terminal operations which takes a Predicate as argument and returns a boolean result by applying the Predicate to the elements of the stream. Predicate might not be applied to all the elements if further execution is not require.
- anyMatch: Returns true if any element found matching with the predicate.Predicate will not be applied to other elements if any matching found.
- allMatch: Returns true if all elements are matching to the given predicate.
- noneMatch: Returns true if none of the elements are matching to the predicate.
Stream.of(5, 10, 15, 20).anyMatch(i -> i % 10 == 0);
Stream.of(5, 10, 15, 20).allMatch(i -> i % 5 == 0);
Stream.of(5, 10, 15, 20).noneMatch(i -> i % 3 == 0);
6.6. Finding element¶
Stream interface has findAny method which returns an arbitrary element from the stream. The behaviour of this operation is nondeterministic; it is free to select any element in the stream because in case of parallelization stream source will be divided into multiple chunks where any element can be returned. It has findFirst method also which returns the first element of the stream.
| Signature: | Optional<T> findFirst() Optional<T> findAny() |
|---|
If you see the signature of above two methods, they return an Optional object which is a wrapper describing absence or presence of the element because there might be chance that these operations were called on empty stream. Don’t worry about Optional now, use get() or orElse() methods to get value from the optional.
Stream.of(5, 10, 15).filter(i -> i % 20 == 0).findAny().orElse(0);
Stream.of(5, 10, 15).map(i -> i * 2).findFirst().get();
6.7. Stream Reduction¶
Stream interface supports overloaded reduction operations that contineously combines elements of the stream until reduced to single output value.
Suppose I asked you to calculate sum of array of numbers, then if i am not wrong your answer would be something like below.
int[] arr = { 1, 2, 3, 4, 5, 6 };
int result = 0;
for (int num : arr) {
result += num;
}
Now, I changed my requirement to calculate multiplication of elements of the array. So you will update your code to result=0 and then result *= num. So if you notice here all the time you will have an initialization logic, an iteration and an operation on the two elements, only your intialized value and the operation varies.
To generalize these kind of tasks Stream API has provided overloaded reduce methods that does the same operation what we saw. If we re-write above codes then they will be
Arrays.stream(arr).reduce(0, Integer::sum)
Arrays.stream(arr).reduce(1, (i1, i2) -> i1 * i2)
T reduce(T identity, BinaryOperator<T> accumulator) The reduce operation here takes two arguments:
- identity: The identity element is both the initial value of the reduction and the default result if there are no elements in the stream. In the
reduce(0, Integer::sum)example, the identity element is 0; this is the initial value of the sum of the numbers and the default value if no members exist in the array. - accumulator: The accumulator function takes two parameters: a partial result of the reduction (in this example, the sum of all processed integers so far) and the next element of the stream (in this example, an integer). It returns a new partial result. In this example, the accumulator function is a lambda expression that adds two Integer values and returns an Integer value:
- identity: The identity element is both the initial value of the reduction and the default result if there are no elements in the stream. In the
Optional<T> reduce(BinaryOperator<T> accumulator)
This is almost equivalent to first reduction method except there is no initial value. Sometime you might be interested to perform some task in case stream has no elements rather than getting a default value. As an example if the
reducereturns zero, then we are not sure that the sume is zero or it is the default value. Though there is no default value, its return type is an Optional object indicating result might be missing. You can useOptional.isPresent()to check presense of result.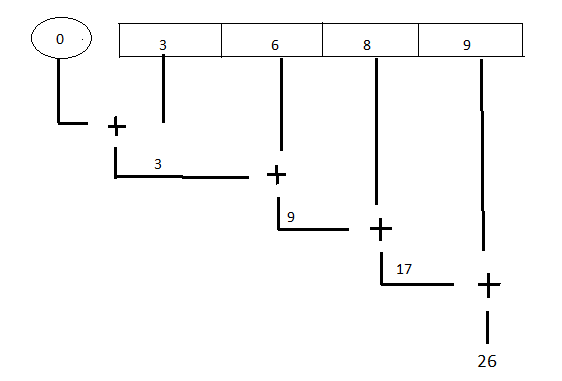
Sequential reduction
U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner) In first two reduction operations your stream element type and return type were same means before using the reduce method you should convert your elements of type T to type U. But there is an 3 arguments reduce method which facilitates to pass elements of any type. So here accumulator accepts previous partial calculated result and element of type T and return type U result. Below example shows the usage of all three reduction operations.
// Find the number of characters in a string. List<String> words = Arrays .asList("This is stream reduction example learn well".split(" ")); int result = words.stream().map(String::length).reduce(0, Integer::sum); Optional<Integer> opt = words.stream().map(String::length).reduce(Integer::sum); result = words.stream().reduce(0, (i, str) -> i + str.length(), Integer::sum);
We saw the sample use of these reduction methods so let’s explore more on this 3-argument reduction operation.
public static void reduceThreeArgs(List<String> words) { int result = words.stream().reduce(0, (p, str) -> { System.out.println("BiFunc: " + p + " " + str); return p + str.length(); }, (i, j) -> { System.out.println("BiOpr: " + i + " " + j); return i + j; }); } output: BiFunc: 0 This BiFunc: 4 is BiFunc: 6 stream BiFunc: 12 reduction BiFunc: 21 example BiFunc: 28 learn BiFunc: 33 well
If you have noticed accumulator function itself calculated the final result and it didn’t even use the last parameter BinaryOperator combiner at all then what the combiner is doing here. So the answer here is parallelization. In the begining of the tutorial I told you parallelization is almost free, there will be very minimal modification (use parallelStream method) require to run your code in parallel. This is not the right time to learn parallelization but i will give you some overal idea just to get the visibility of combiner in this reduction operation.
In parallelization the whole input data set is splitted to multiple chunks, each chunk process individually and combine all the results at the end. So in the above example, complete word set are splitted to groups then they will calculate total number of characters in each group finally sum all these partial results.
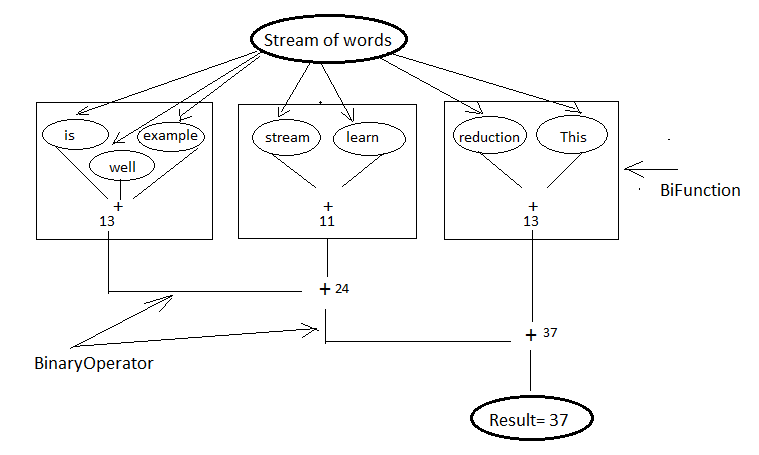
Parallel reduction
Now re-run the code in parallel (words.parallelStream()...) and look into the output. Combiner calculate the sum of two partial results.
BiFunc: 0 This BiFunc: 0 stream BiFunc: 0 well BiFunc: 0 learn BiOpr: 5 4 BiFunc: 0 reduction BiFunc: 0 example BiOpr: 9 7 BiOpr: 16 9 BiFunc: 0 is BiOpr: 2 6 BiOpr: 4 8 BiOpr: 12 25
6.8. To Array¶
Stream interface supports two overloaded toArray methods that will collect stream elements as an array.
- Object[] toArray():
This is the simplest form of toArray operation which returns an Object array of length equal to Stream length.
Example: Integer[] arr = Stream.<Integer>of(10, 20, 30, 40, 50).toArray();
- T[] toArray(IntFunction<T[]> generator):
You saw the first toArray method always returns array of Object type, but this overloaded method will return array of desired type. It accepts an IntFunction as argument that describes the behaviour of taking array length as input and returns the array of generic type.
Employee[] arr = employees.stream().filter(e -> e.getGender() == MALE)
.toArray(Employee[]::new);
OR
employees.stream().filter(e -> e.getGender() == MALE)
.toArray(len -> new Employee[]);
6.9. Infinite Streams¶
We already discussed, Streams can be derived from different sources:
- From array - Arrays.stream(T[])
- From known elements - Stream<String>.of(“Stream”, “is”, “great”)
- From file - Files.lines(Paths.get(“myfile.txt”))
Please visit the Stream sources section for basics of stream sources. The streams generated from above sources are bounded streams where elements size is known. Stream interface supports two static methods Stream.iterate() and Stream.generate which returns infinitite streams that will produce unbounded stream. As generated stream will be unbounded , it’s necessary to call limit(n) to convert stream into bounded.
Note
You can use findAny or findFirst terminal operations to terminate the stream if you assure required result is exist in the stream. Example:
Stream.<Integer>iterate(1, v -> v + 3).filter(i -> i % 5 == 0).findAny().get())
Here we are sure that there will be an element which will be divisible by 5 so you can use findAny to terminate the stream.
- Stream.iterate:
: Signature: Stream<T> iterate(T seed, UnaryOperator<T> f)
It returns an infinite sequential ordered Stream produced by iterative application of the given function. The function here is a UnaryOperator which uses the previous calculated result to produce next result. It also accepts a seed value that will be supplied to the UnaryOperator as initial value.
// Generating fibonacci numbers of a given length
Stream.iterate(new int[] { 0, 1 }, a -> {
int next = a[0] + a[1];
a[0] = a[1];
a[1] = next;
return a;
}).limit(10).map(a -> a[0]).forEach(System.out::println);
Output: [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
- Stream.generate:
: Signature: Stream<T> generate(Supplier<T> s)
It returns an infinite sequential unordered stream where each element is generated by the provided Supplier. As we know Supplier doesn’t accept any argument so the
generatordoesn’t depend on previously calculated value. Below example generates UUID values of a given length.Stream.generate(UUID::randomUUID).limit(5).forEach(System.out::println)